Unlike the workflows that previously surrounded printed content, today’s workflows contain more changing variables, especially when it comes to documentation. Documents are created, repurposed, archived, retrieved, and even merged into others. In short – they encompass change. As a result, keeping an eye on change is an essential part of document management.
What is Metadata and Why Use it?
Metadata is descriptive information about data. It can be embedded into a PDF file (as XML) to help identify its contents or characteristics during its travels. Examples of metadata include: author names, document title, subject description, source type, etc.
Metadata can help manage change. When businesses integrate metadata into their work flows, they can better track their document life cycles and stay ahead of document changes more effectively. However, as businesses grow and integrate metadata, they often introduce:
- Large amounts of unstructured metadata. For example, documents that are appended or merged with others acquire additional metadata along the way.
- Different frameworks to address the problem of unstructured metadata. However, such frameworks hamper the efficiency of dissimilar systems to interchange or process information.
In and of itself, metadata is often used to address (short-term) document life cycles, especially within localized environments. However, if the volume and exchange of documents increases, so does the complexity of the corresponding metadata. Is there an alternative way to handle such document assets more effectively? This is where XMP attempts to position itself as a viable option.
What is XMP Metadata and Why Use it?
Introduced by Adobe in 2001, the Extensible Metadata Platform (XMP) is a labeling specification, based on the W3C Resource Description Framework (RDF). XMP provides a (cross-platform) format for creating, processing, and interchanging metadata.
Therefore XMP (metadata) is a type of metadata that adheres to specific standards that dictate how data is organized and accessed. XMP metadata can be embedded into PDF documents, HTML, SVG, XML files, and image formats such as JPEG, TIFF, PNG, GIF, etc.
Designed as a type of encapsulating framework, XMP can act as a bridge between different systems that need to exchange and use metadata. When it comes to documentation, embedding XMP metadata into PDFs improves their searchability and integration into existing work flows. In addition, long-term archiving standards such as PDF/A-1a and PDF/A-1b require the use of XMP to identify that their contents are PDF/A compliant.
Embedding Intelligence into PDFs
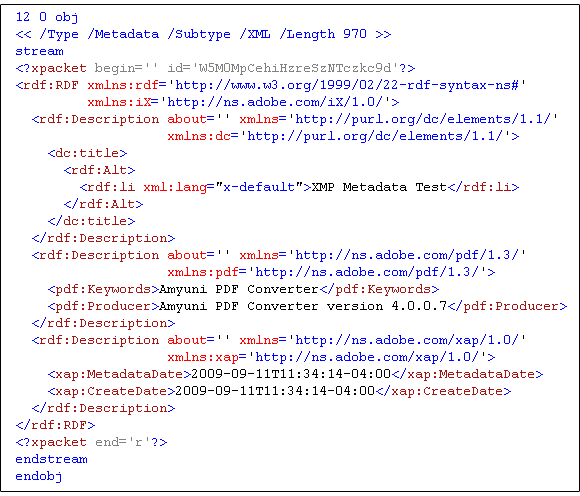
Documents become smart assets when they are accompanied with XMP metadata. Once data is embedded in a PDF file as an XML packet (Figure 1) it stays with the file so it can be recycled and repurposed across different platforms or content-management systems.
Figure 1: XMP Packet Within a PDF Object
Customizing XMP
Because embedding XMP metadata differs slightly for portable document formats, developers should already be familiar with the XMP framework specifications and also how to work with the right XMP-enabled tools. An example of a such a tool is the Amyuni PDF Creator. Unlike other XMP-enabled tools which can only include standard XMP metadata, the Amyuni PDF Creator enables developers to include their own customized XMP schemas. This ability gives developers and document managers more authoring, tracking, and archiving options.
In part 2 of this article, we shall look at how a product like the Amyuni PDF Analyzer can be automated on a server to embed custom XMP schema extensions into PDF/A documents.
| Franc Gagnon is the technical copywriter for Amyuni Technologies www.amyuni.com |
Comment