Amyuni Technologies Blog
In a previous article, we reviewed the benefits and uses of PDF metadata. Specifically, we looked at the emergence of XMP metadata as a potential standardization for metadata frameworks and at how it can help PDF developers store, exchange, track, and retrieve information. In this article we will explore the injection of custom XMP metadata tags into existing PDF/A documents.
PDF/A and XMP: Inevitable Convergence
In 2001, developers recognized the need to add their own customized XMP metadata tags to PDF documents. They understood that by adding their own information, they could make a document easier to retrieve and include data that would not change regardless of where or how it was processed.
However, the introduction of the PDF/A standard has challenged some developers and has forced them to rethink how they would incorporate their XML customizations, especially into PDF/A documents. They realized that although there were many ways to add custom XML tags, there were only a few ways to keep their new data valid without compromising the PDF/A’s format restrictions.
Because of the rising popularity of PDF/A, Amyuni Technologies saw the need to provide developers with a tool that would help them solve specific PDF challenges, such as working within the confines of ISO archiving standard. This tool is the PDF Analyzer.
PDF/A: Driving Archiving and Document Conformance
One example of inserting customized XML information into PDF/A documents is with ERP purchasing applications. Often, developers use these applications to generate invoices or purchase orders in PDF/A for archiving and retrieval purposes. Although these files already contain XMP metadata, additional information can be added to make these files more useful—extractable information from the text content itself.
Items such as P.O. numbers, contact details, or the names of sales persons, departments, authors, and projects are all valuable pieces of information developers can use to create reports and enhance document retrieval. Developers can automate PDF Analyzer to:
- Verify the internal structure of incoming PDF/A purchase orders from an ERP application for PDF/A compliance and repair them if necessary (and possible).
- Locate and extract specific text strings (names, addresses, dates, etc.) from the PDF/A documents and convert them into XML (Figure 1).
Figure 1: Using PDF Analyzer to Extract and Convert Text Strings
- Take the XML and create customized XMP extension schemas.
- Reinsert the new customized XMP extension schemas into the XMP streams of the PDF/A documents.
- Resave the document PDF/A and still keep its adherence to the ISO specifications.
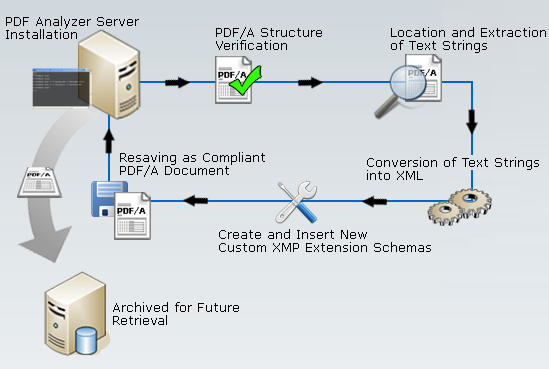
Figure 2 outlines how this automated text conversion process would operate, either for single or multiple PDF/A documents:
Figure 2: Text String to XMP Metadata Workflow
When companies implement PDF/A, it’s often because they have high volumes of documents that require archiving. Insurance companies, banks, medical institutions, and manufacturing companies are just some examples of where the PDF Analyzer’s automation and XMP customization capabilities can bring a higher degree of efficiency to their documentation workflows.
Learn more about PDF Analyzer at www.pdfanalyzer.com.
| Franc Gagnon is the technical copywriter for Amyuni Technologies www.amyuni.com |
Comment